


Coffee break series: Decoding the ML project life cycle
We are back with our coffee break series. In the last post, we walked through the “High-level ML system design”. In this article, we will be looking at the steps in an ML project life cycle in detail.
Machine Learning is the hottest trend in the industry. Every business is trying to integrate Machine Learning in their projects to ride on the wave of AI. The starting point of integrating Machine Learning is understanding the project life cycle of a Machine Learning project.
We are back with our coffee break series. In the last post, we walked through the “High-level ML system design”. This post was about understanding the blueprint while designing an ML solution.
We covered the following steps in detail:

To stay in touch and support us, please subscribe to Coffee and Engineering
In this article, we will be looking at the steps in an ML project life cycle in detail. After reading this post, you will be able to:
Understand and define Machine learning project life cycle
Let’s get started before your coffee gets cold!
1. Data Ingestion/Collection
Collecting the data is the first and most important step in an ML project. The data is generally raw because it is directly obtained in real-time from various sources, it could be Web server logs, RDBMS data, NoSQL data, Social media, sensors, IoT data and Third-party data, and stored in a Data Lake as an example.

2. Data Preprocessing
After all the data has been stored, this data should be assessed to see if the data has:
Outliers
Missing value
Inconsistent value
To rectify them, there are a couple of data preprocessing techniques to remove outliers and impute missing values.
The next step is Feature Engineering in which the right attributes are selected from the cleaned data. This is done by keeping the domain and context in mind. It can also be automated by applying a chi-squared statistical test to rank the impact of each feature for the prediction purpose. Doing so will improve the accuracy of the predictive model, reduce the computation expensiveness.

3. Data Segregation
One of the important requirements of a machine learning model is that it is able to generalize well on unseen data. To ensure this, the data used can be segregated into different units into:
Training and testing dataset
Training, testing and validation dataset
The primary goal is not only to achieve high training accuracy but also to perform well on unseen data. A common approach to split data is usually dividing it in 70-30 ratio, where 70% goes into training the model and the rest is used to evaluate as test data. In the second approach, 70% can be used for training, 20% for testing and the rest 10% for validation
4. Model Training
The schedule of a Model training pipeline varies depending upon the application hence it could be every couple of hours to once a day. It can also be time scheduled or based on certain event trigger.
In this step, the training data subset undergoes for training a Model. There are a bunch of algorithms like Linear Regression, Random Forest, Decision Tree etc. The Process can be parallelized too by having a dedicated pipeline for each model that runs simultaneously which will help in choosing the best one. Post-training, the learned parameters, metadata on the training set, accuracy, timings, will be saved in the Model Candidate Data Store Repository.
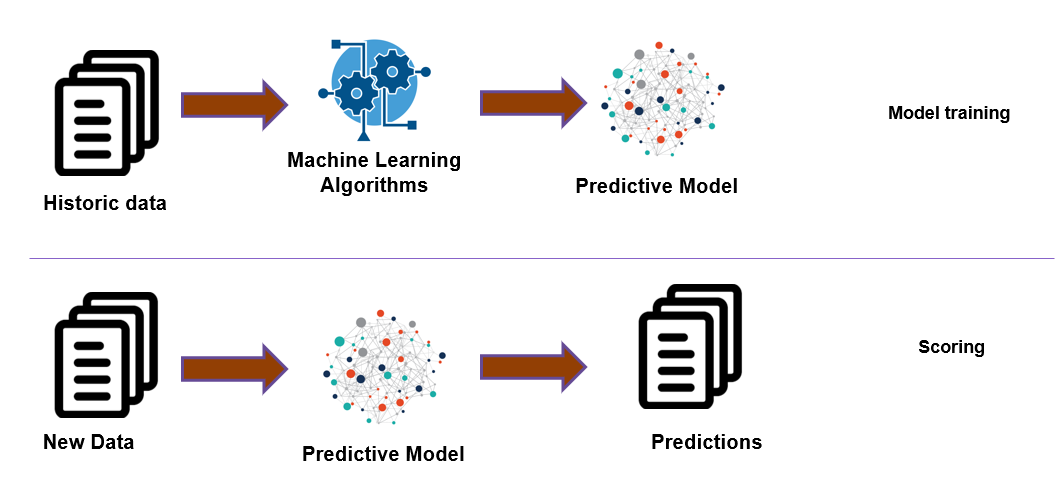
5. Model Evaluation
To assess the Model Performance, Test data is brought in to see how well the Model is able predict.
Models from the Model Candidate Data Store repository are selected and evaluated on the test data. A library of several evaluators is used to provide a model’s accuracy metrics (e.g. ROC curve, PR curve). Hyperparameter optimization as well as regularization is also done to come up with the final model. This Final Model is then marked for deployment.
6. Model Deployment
Once the Final Model is ready, it is pushed for deployment for offline (asynchronous) and online (synchronous) predictions. More than one models can also be deployed at any time to switch between old and new models as a backup option. Deploying it to a container and running it as a microservice to process on-demand prediction is an efficient way for offline. Whereas online, the model can be deployed in a container to a service cluster, generally distributed in many virtual machines for load balancing to ensure high scalability and low latency throughput.
7. Model Serving/Scoring
When a deployed ML Model is set to make predictions on the new unseen data solving the business problem is known as Model Serving.
Model scoring generates the output of the given model. The term Score is used rather than Prediction because the outcome varies. For example-
A Classification Model will have a predicted class as an outcome
A Linear or Regression Model will have a numeric value as an outcome
List of Recommended items
8. Performance Monitoring
The Model has to be continuously monitored on how it is performing in the real world. Whenever there are new predictions being served, its results are evaluated and analyzed by comparing them to the results generated during Model Training. Logging analytics tools like Kibana, Splunk, Grafana are used commonly. For the consistent ML System Design, the scores are measured to see if there is any shift in prediction so that model can be restructured.
Summarizing, Data is collected from a source, Cleaned for extracting features, Split into Test/Train subsets, Trained and Evaluated, Once evaluated then Model is pushed for Deployment on Web Endpoint such as Flask etch and is Monitored continuously to observe consistency.
Conclusion
The ML project goes through a number of stages that are crucial to deploying machine learning models. It is said that 90% of machine learning models never go into production. By understanding the ML project life cycle properly, you can ensure that you are one of the ten data scientists whose machine learning model goes into production.
In this post, we covered:
Different stages involved in a machine learning project
We hope that the post would have helped you in structuring your ML Project.
Have a Nice Day and Subscribe to CafeIO and Engineering if you haven’t already subscribed.
So detailed info