


ML Models as Serverless Functions
Ready to deploy your machine learning model and can't choose from the options? Coming to the rescue is our article on ML Models as Serverless Functions to help you navigate between options.
Taking Machine learning models to production is the ultimate aim. Making a software system available for use is called deployment. Scalability is the property of the system to handle a growing amount of work by adding resources to the system.

More often than not, the problem of Model serving is soon visited by the challenge of making the deployment scalable. The deployment can be done as
Web Endpoints
Serverless functions
A deployment using “Model as web endpoints” style will revolve around the following keywords, Model persistence, REST API, Flask framework and Dash, Heroku, HTTP servers: WSGI and Gunicorn
In this post, we will focus on deploying models Serverless.
Introduction to models as Serverless functions
Managed vs Hosted solutions
Cloud functions
Lambda functions
PaaS vs Serverless
Deploying Machine Learning Model - A Schematic View

If you like our writing, do encourage us by Subscribing and Sharing
Introduction - Models as Serverless functions
Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform.
Martin Fowler's Blog on Serverless
Serverless functions enable coders to deploy their machine learning models without worrying a lot about maintaining servers and choosing between options. The model can be deployed in three simple steps:
Write codes that satisfy your requirements
Specify a list of dependencies
Deploy the function into production
That is all! This is how easy your deployment process becomes.
Machine learning Systems has a constant feedback loop of receiving new data continuously which is needed for a retraining cycles. This is an additional complexity which adds to the list of operational challenges. Serverless patterns enable a decoupled design and promote microservice based architecture enabling separation of concerns which helps towards maintainability. At the same time they are not the silver bullet and carry the drawbacks of microservice architecture.
Our quest for deployment ended on Heroku which is basically a Platform as a service (PaaS) that enables you to deploy your machine learning model with minimum codes. An extension and addition to that are Serverless functions.
Managed vs Hosted solutions
These are the two major solutions being provided for deployment:
In managed solutions, the cloud service providers avail the responsibility of provisioning servers and maintaining them.
Whereas in hosted deployments, the provisioning of servers is done manually.
Serverless technologies, encompassing managed services support data engineers to single-handedly manage a huge amount of data load.
Thoughts to support Decision making: Managed vs Hosted solution?
What amount of latency is permitted in your system?
Is your system scalable to match huge workloads?
Are you iterating on a system in production?
Can you chip in extra money for the Serverless cloud?
Cloud Functions (Google’s way of doing Serverless)
Google Cloud Platform (GCP) provides support for Serverless functions which are called “Cloud functions”. The best part about GCP is that it closely resembles the python development environment which might be easier for data scientists to become accustomed to.
Time to get some hands-on practice!
While we can explore GCP through its interface, we will be integrating a tutorial on interacting with it using the command-line interface. The steps we discuss are as follows:
Install the libraries
Create a bucket: A bucket is essentially all the files stored on GCS and they are expected to have unique names.
Save the file
Downloading model to your local machine
Let’s have a look at the codes:
| #Installing libraries | |
| pip install --user google-cloud-storage | |
| export GOOGLE_APPLICATION_CREDENTIALS=dsdemo.json | |
| #Creating a bucket | |
| from google.cloud import storage | |
| bucket_name = "cafeIO_project" | |
| storage_client = storage.Client() | |
| storage_client.create_bucket(bucket_name) | |
| for bucket in storage_client.list_buckets(): | |
| print(bucket.name) | |
| #Saving the file | |
| from google.cloud import storage | |
| bucket_name = "cafeIO_project" | |
| storage_client = storage.Client() | |
| bucket = storage_client.get_bucket(bucket_name) | |
| blob = bucket.blob("serverless/logit/v1") | |
| blob.upload_from_filename("logit.pkl") | |
| #Downloading the file on local machine | |
| import pickle | |
| from google.cloud import storage | |
| bucket_name = "cafeIO_project" | |
| storage_client = storage.Client() | |
| bucket = storage_client.get_bucket(bucket_name) | |
| blob = bucket.blob("serverless/logit/v1") | |
| blob.download_to_filename("local_logit.pkl") | |
| model = pickle.load(open("local_logit.pkl", 'rb')) | |
| model |
After initiating a bucket in the GCP, we can integrate our predictive model. In order to improve performance, we can cache the model so that the latency of the model can be reduced further.
Lambda functions (AWS’s way of doing Serverless)
The ecosystem provided by Amazon for model deployment is called Lambda. It is useful to integrate various components within the AWS deployment ecosystem as the platform can be integrated into one place. One point of difference between GCP and AWS is that while GCP is closer to the Python environment, AWS can be a little tricky to deal with.
You can create a bucket and set up a user and provide them with access before integrating it with your predictive model.
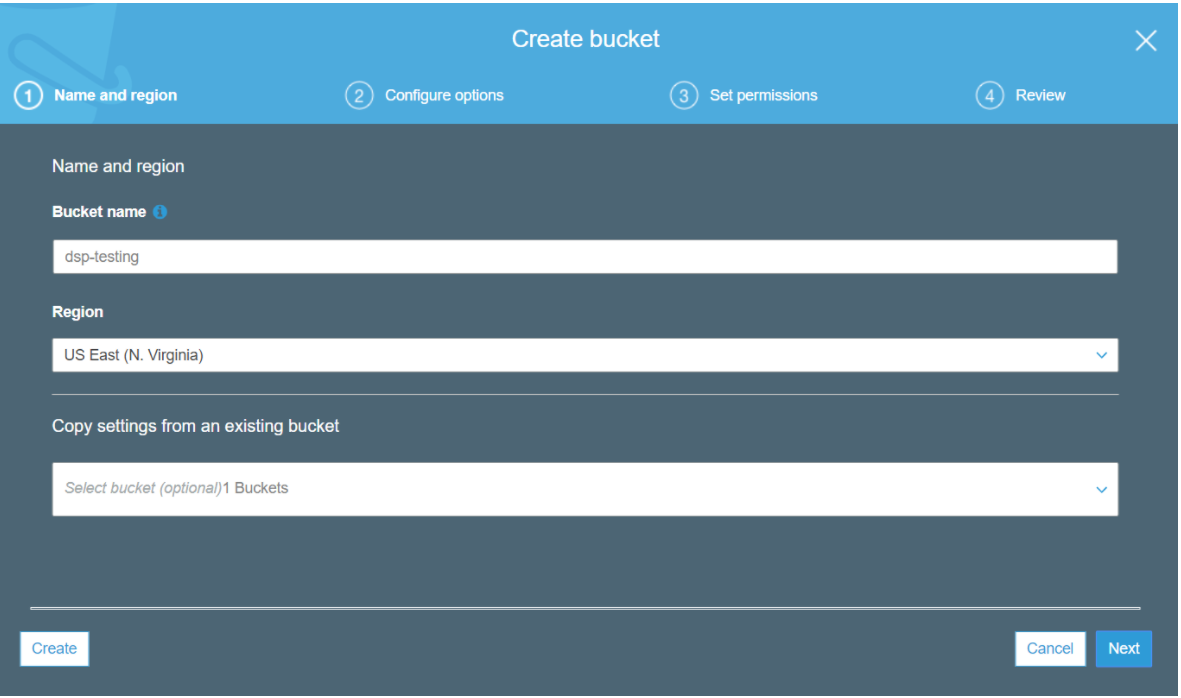

The workflow in AWS Lambda is depicted below:

PaaS vs Serverless function
Going a little beyond Serverless
Platform as a service (PaaS) provides an infrastructure for developers to focus on web frameworks and optimizing their codes rather than planning and working on infrastructure end-to-end. A suitable example of PaaS is Heroku.
Serverless functions like Lambda can be an attractive option when you can tolerate slightly higher latency and your code requirements are not that heavy. They are also useful when you are working with other components within AWS so that it gels well. PaaS like Heroku can be a better choice when you don’t want to deal with multiple functionalities.
Overall, it can depend on a case-by-case basis as to which would be preferable.
Conclusion
In this post, we saw how models can be deployed with Serverless functions. This post gives us in-depth insights into how web endpoints can be created and deployed as Serverless functions. Furthermore, we saw two very famous Serverless functions: GCP and Lambda and also compared PaaS and Serverless functions.
Next, we will be discussing containers and how they can be helpful in taking your machine learning model to production.
Do share, comment and subscribe to Coffee and Engineering.